Final Report
Summary
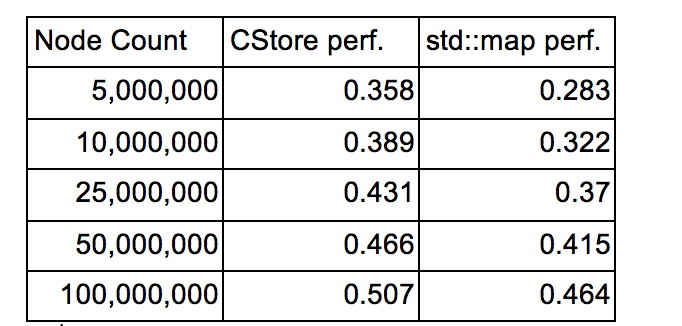
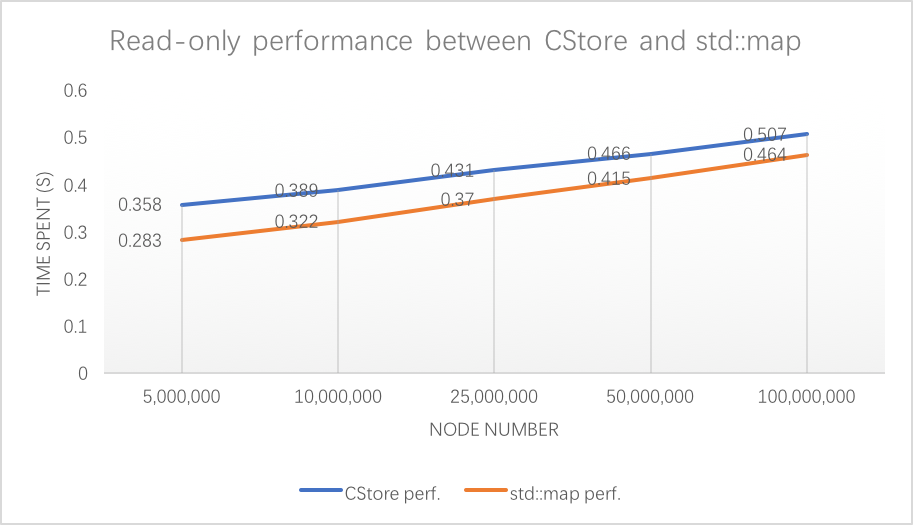
In this project we implemented a lock-free SIMD skiplist which supports insert, delete and find. The project deliverable will be the library for this skiplist, and performance comparison with std::map and other lock-free non-SIMD skiplist on GHC machines.
Background
According to Wikipedia, skiplist is a data structure that allows fast search within an ordered sequence of elements. On average it costs O(logN) to do searches.
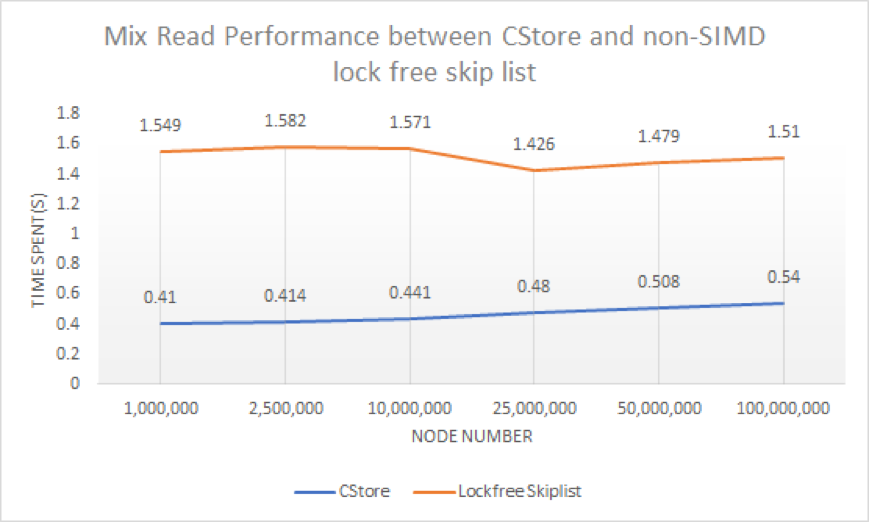
However, since skiplist is an array of linked lists, and linked list has poor data locality (because it has to load memory again when going to a new node, as the example in the following graph shows), so it is actually slower than balance tree implementations like red-black tree.
The workload of all the three operations can be break down into index searching part and storage layer operation overhead. In index search part, only within each node of index layer, we are able to make use of data parallel and apply SIMD comparison. Since the next index node in the searching path depends on the comparison result in the previous index node, we are not able to parallelize the comparison on multiple index node within one query. In the storage layer, we implemented a lock-free linked list to minimize the synchronization overhead. In this part, there is not much data parallelization can be applied.
Figure 1. Skip List has poor data locality
One solution we apply in CStore is we group adjacent indexes together to improve data locality, and this also introduces the chance of applying SIMD to do comparisons and reduce the number of comparisons we have to do to search indexes horizontally.
Another case is we have to handle the multi-threading scenario. There has been some lock-free solutions for skiplist, but since we are changing the structure of skiplist, they cannot apply in our case. We make use of the lock-free linked list solution and come up with some adaptations to suit our design and maintain the lock-free attribute.
Approach
Overall structure design:
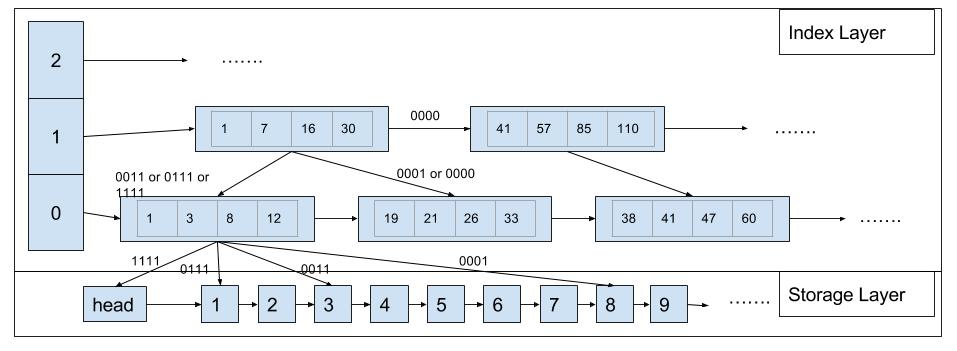
Figure 2. Architecture of our SIMD skiplist
Above is a representation of the architecture of our skiplist. We divide the skiplist into index layer and storage layer. In the index layer, we group multiple indexes of a node together in one index node, so we can make use of cache locality and apply SIMD comparisons. The index layer will not change until some upper limit of the number of inserts and deletes are triggered, in which case we will build a new index layer to replace the old one. Our assumption is the requests are uniformly distributed on the key space, so making the index layer unchanged for some time will not hurt performance much. In the storage layer, we only have an ordered singly-linked lock-free skiplist.
Index layer design:
Each index node holds VECTOR_SIZE number of indexes. On receiving a query, each index node will launch a gang of instances, each instance comparing the key to an index and report the result in the corresponding slot in the output array. Then we use the pre-built routing-table to find where to go next. VECTOR_SIZE is a configurable parameter, on GHC machine we can use avx instruction set which can compile 8-width vector, so a VECTOR_SIZE greater or equal to 8 is preferable. But a large vector may lead to excessive computation, since in skip lists most of the time we suppose the target key is in the middle of the indexes. After doing test with various data size, a VECTOR_SIZE of 8 proves to have the best performance.
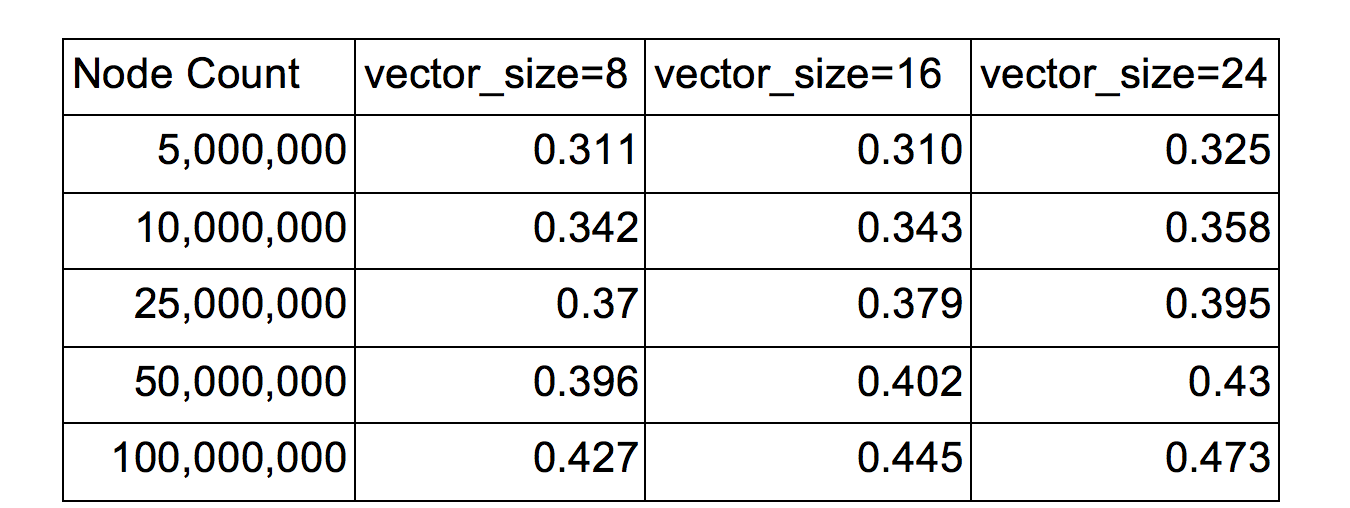
Table 1. Query time with different vector sizes
(thread number = 16, total requests = 32M, read-only test)
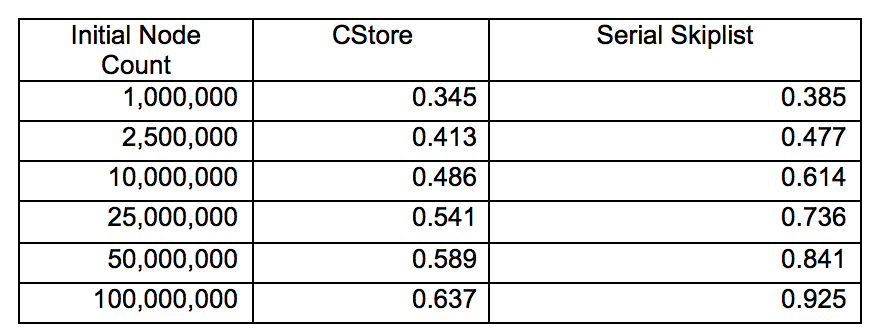
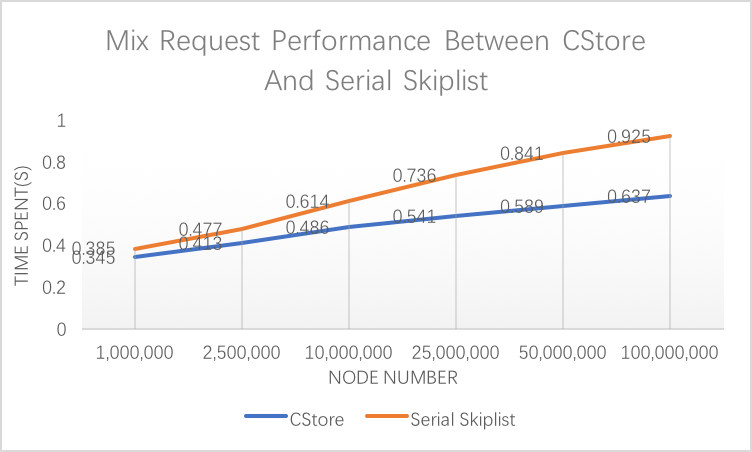
We choose to not change the index layer on inserts and deletes and only rebuild it at some interval because if we do change the index layer, we will not only have to do index movement frequently which takes time, and we will also have to come up with a lock-free/fine-locking performant index layer. This leads us to give up this plan and turn to our current solution.There is no parallelism in building the index layer, because anyway we have to go through the entire storage layer and the storage layer is a linked list which is hard to do data parallelization. We have a configurable parameter REBUILD_THRESHOLD to denote the maximum number of inserts and deletes before a rebuild of index layer. This parameter should be decided based on the number of nodes stored. In our testing, it is definitely not suggested to do frequent rebuilding, because going through the whole list to rebuild consumes a lot of resources. But scarcely rebuilding the index layer may also lead to slow lookups, so it is a tradeoff and this parameter needs to be carefully tuned. In our testing, based on a test setting of 500k intial nodes, 32 million requests with 60% inserts, 20% reads and 20% deletes, and 5 billion key space, 1/100, 1/5 and 2 times of the number of nodes all prove to be a good threshold.
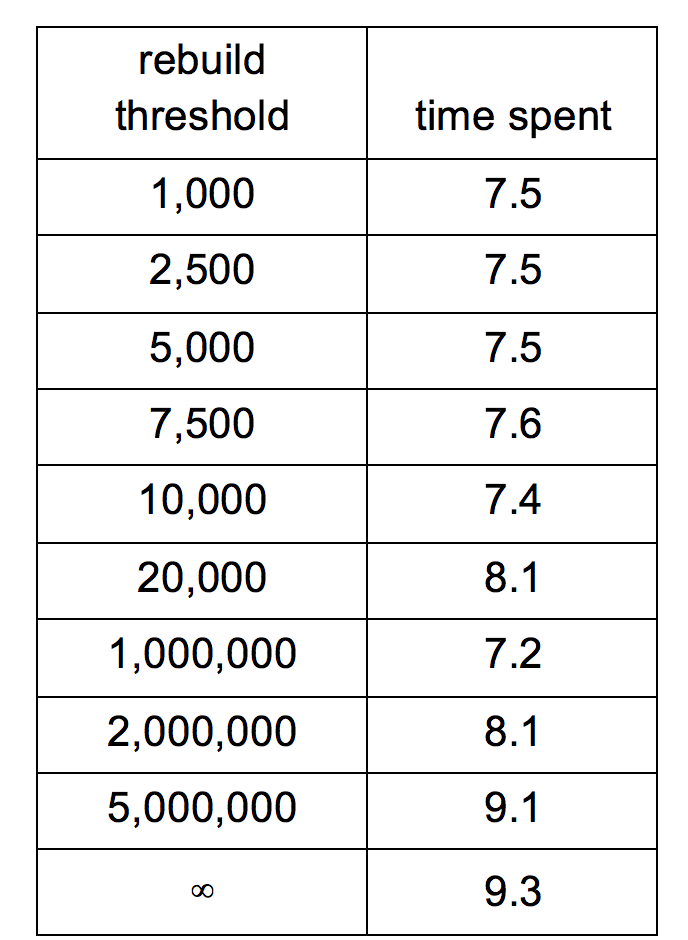
Table 2. Query time with different rebuild threshold
Storage layer design:
Our storage layer is an ordered linked list, so we first turn to lock-free linked list solution suggested by Harris[1]. The main idea is to utilize single-word compare-and-swap to implement lock-free insert, search, delete operations. In insert operation implementation, we first find the right position we need to insert our node to. As shown in Figure 3, we are trying insert B between A and C. We set the node B’s next pointer to the node C. Then we try to set node A’s next pointer to node B using CAS. If CAS failed, we start from the very beginning, search the position to insert the node again.
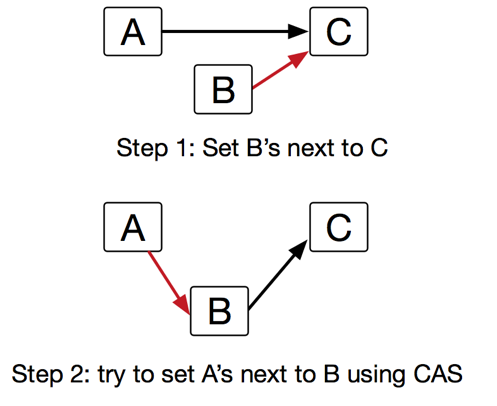
Figure 3. Lock-free Linked List Insertion Steps
Harris’s lock-free delete solution is utilizing a special mark bit at the last digit of next field. We use two separate CAS operations to perform a two-step deletion. The first step is used to mark the next field of the deleted node. By doing so, we logically delete the node. No more unsafe operation will perform to the logically deleted node. The second step is to physically delete the node.
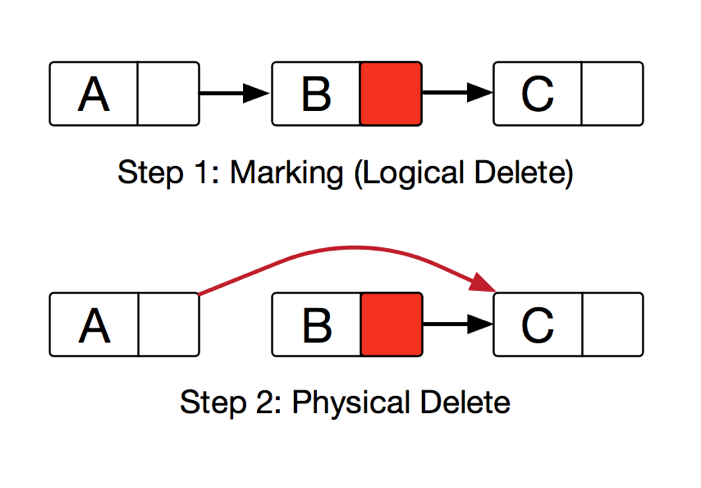
Figure 4. Lock-free linked list delete steps
However, this two-step deletion is not enough in our situation. We have index layer which holds the pointers to the node in storage layer. We cannot physically delete a node without the “confirm” from index layer. To address this, we introduced an extra mark bit which we called the “confirm delete” mark to indicate that index layer confirmed the deletion of this node. This will only happen when we are rebuilding a new index layer. At that time, we will traverse the nodes in storage layer. To rebuild a new index layer, we skip the logically deleted nodes and marked them as confirm deleted. A node is safe to be physically deleted after it is marked as “confirm delete”.
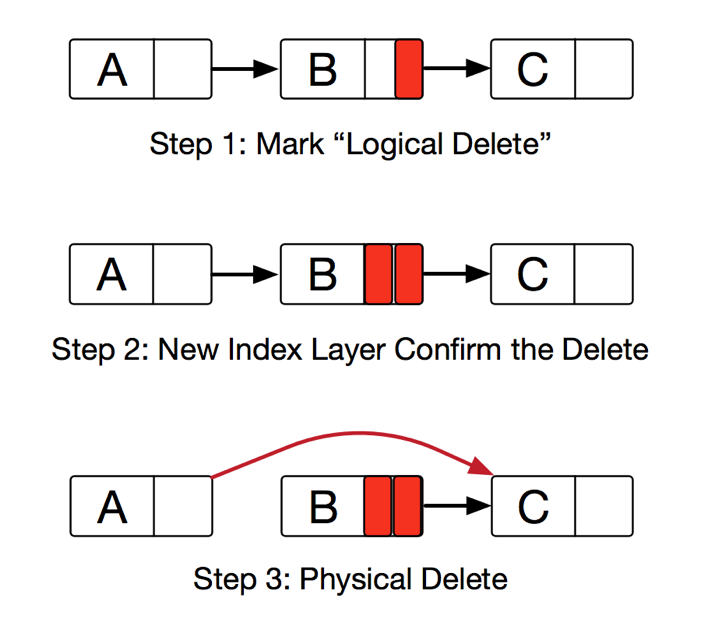
Figure 5. Lock-free CStore storage layer delete steps